

Have you ever wondered how LLMs ‘read’ text and seem to understand concepts? Internally, these models turn their input into numerical vectors. This means that with an LLM and some text input, you can get a bunch of numbers for your neural network, or whatever machine learning model you dream of, to work with. For example, this exact paragraph turns into this when you pass it through the OpenAI embeddings API (text-embedding-ada-002):
[
-0.015850013,
0.0026720716,
0.020836078,
-0.013748839,
0.0033797822,
0.010857191,
0.0044793515,
-0.018728148,
-0.044807028,
-0.04067224
... (1526 more numbers)
]
Now, if the vectors produced are just random numbers, this would be pretty much useless (you might as well use sha256). However, the trick that makes these numbers useful is that they represent the conceptual meaning of the text, and text which means very similar things turn into vectors that are closer together. For example, consider the following 4 sentences:
If you pretend for a sec that the vectors are two-dimensional, they might look like this:
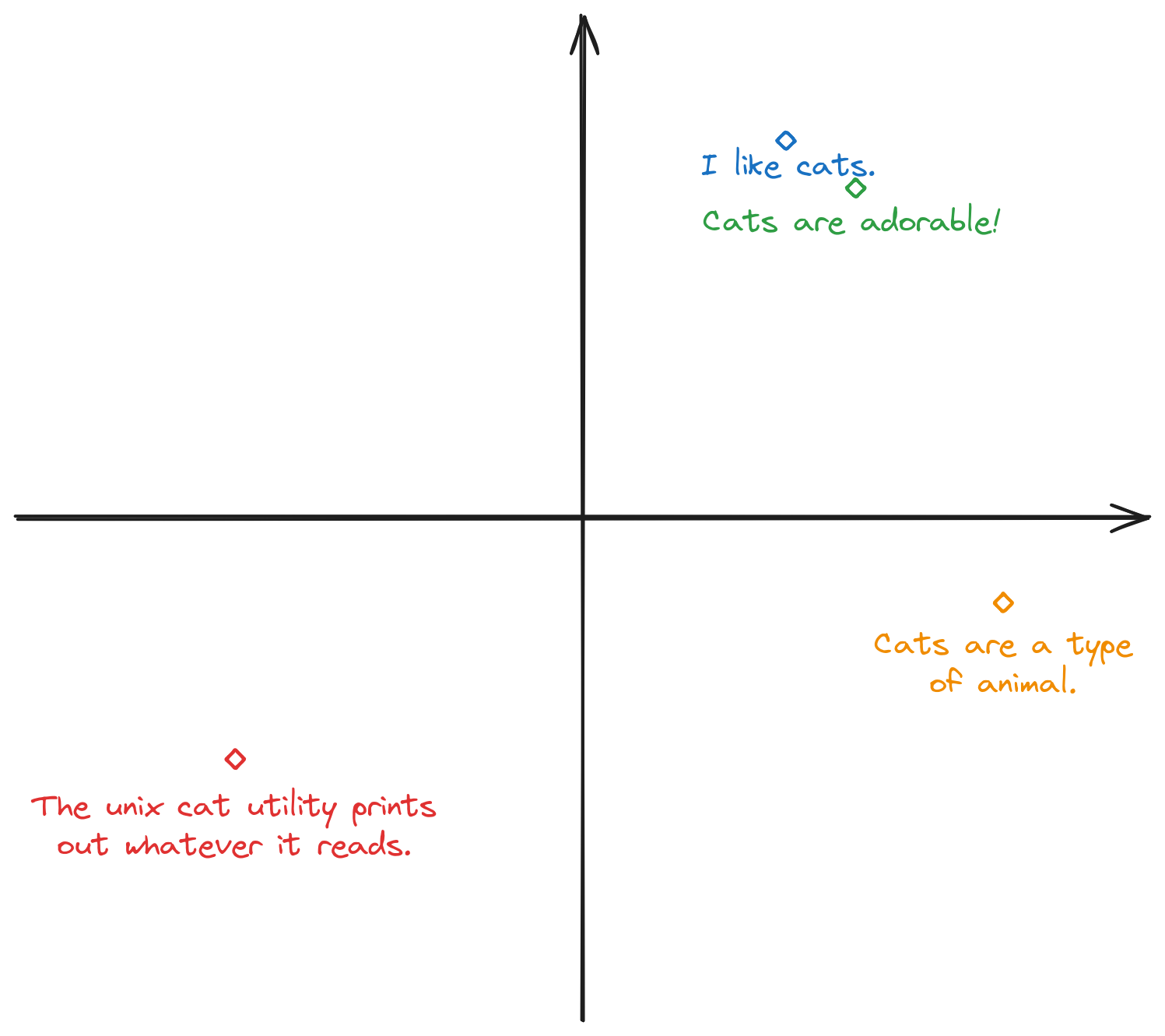
While real embeddings have many more dimensions and the pattern would not be this clear-cut, the intuition will still apply. For example, sentence 1 and 2 will have vectors that are very close to each other, sentence 3 will be a bit further away (but will still be pretty close since it's still talking about cats), whereas sentence 4 will be the furthest away from all of 1, 2, and 3 (since it isn't even talking about the animal cat anymore).
You can play around with embeddings a bit more in the below interactive tool. Try putting in several similar or dissimilar sentences and see how the similarity score changes. The tool will highlight the input that's most similar with the first input. In practice, abstract concepts like ‘happy’ or ‘sad’ also meaningfully correlate with sentences that have those properties, so you can also try putting in a generic sentence, then the words ‘happy’ and ‘sad’ and see which word is most “similar” to your first input.
It's worth saying that while useful as a demo, comparing the similarity of sentences with abstract concepts like “happy” or “sad” is probably not the best way to do classification. If you have a reasonably-sized dataset, you can probably train a regression or neural network to do the classification based on the embeddings.
« home